gemini-web2api
공짜 Gemini를 OpenAI API처럼 쓰는 단일 파일 프록시
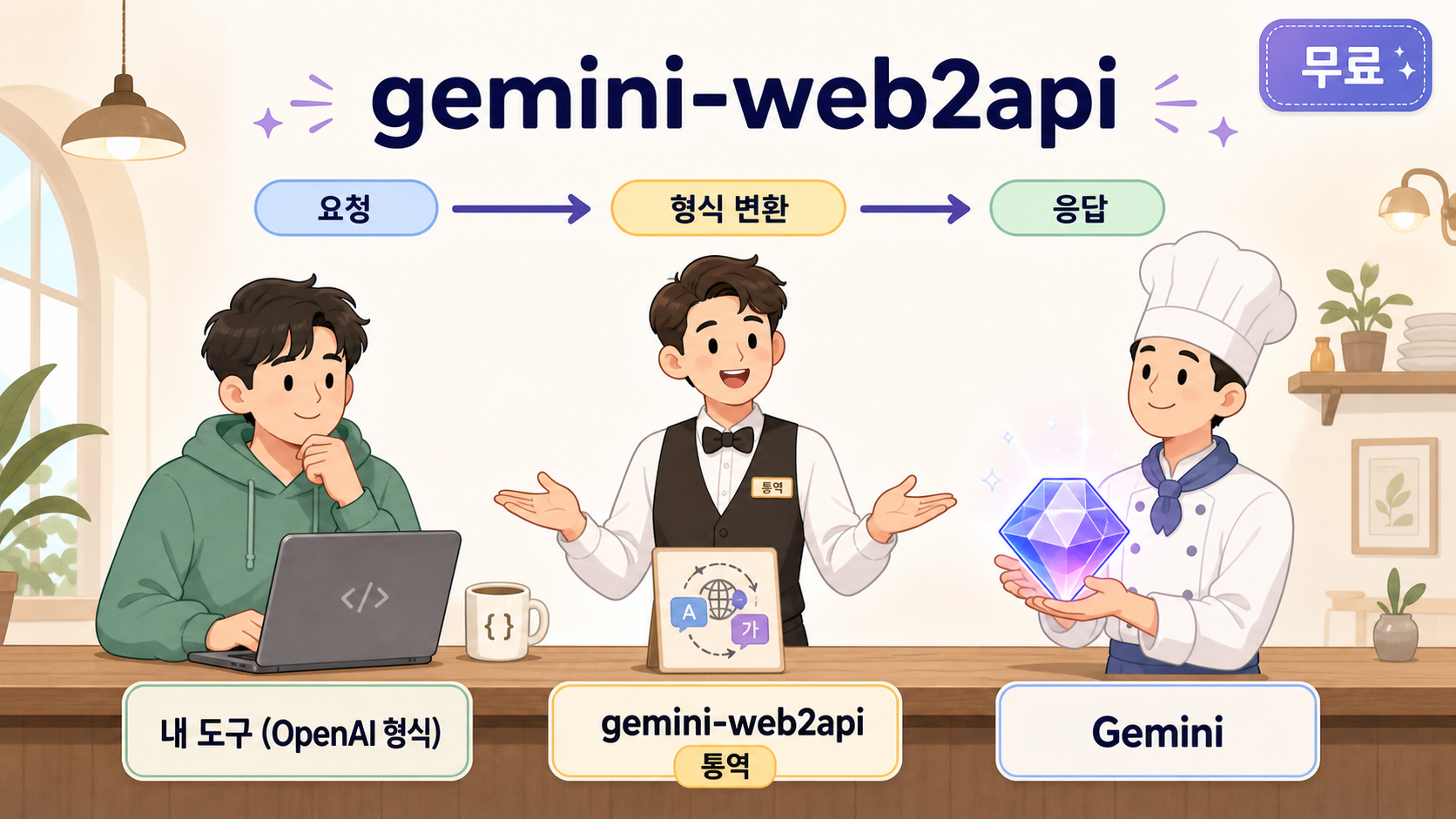
이건 뭐예요?
해외 여행을 가서 식당에 들어갔는데, 메뉴판도 종업원 말도 다 외국어라면 막막하죠. 그럴 때 옆에서 통역사 한 명이 "이분은 이걸 주문하고 싶대요" 하고 양쪽 말을 바꿔주면, 우리는 평소처럼 한국어로 말해도 주문이 술술 됩니다. gemini-web2api(제미나이 웹투에이피아이) 가 하는 일이 딱 이 통역사예요.
조금 더 풀어볼게요. 요즘 AI 도구들은 대부분 OpenAI(오픈AI, 챗GPT를 만든 회사) API 형식으로 말을 겁니다. "AI한테 질문 보낼 땐 이런 모양으로 보내라"는 일종의 표준 양식이 있는 거예요. 그런데 우리가 구글 Gemini(제미나이) 를 쓰고 싶다면 양식이 안 맞아서 그냥은 못 붙입니다.
gemini-web2api 는 그 사이에 끼어서, OpenAI 양식으로 들어온 질문을 Gemini가 알아듣는 양식으로 바꿔주고, Gemini의 답을 다시 OpenAI 양식으로 되돌려줍니다. 이렇게 양쪽 말을 중계해 주는 프로그램을 프록시(proxy, 중계 서버) 라고 불러요.
여기서 진짜 재미있는 부분이 있어요. 이 프록시는 정식 Gemini API에 돈을 내고 붙는 게 아니라, 여러분이 브라우저에 이미 로그인해 둔 Gemini 웹(브라우저에서 쓰는 그 제미나이) 의 세션을 빌려서 동작합니다. 그래서 만든이가 내건 슬로건이 이거예요 — "Zero cost · cross-platform · single file" (추가 비용 없이 · 어느 환경에서나 · 파일 단 하나로).
- 만든이: GitHub Sophomoresty 님
- 라이선스: MIT (자유롭게 쓰고 고치고 배포해도 되는 가장 너그러운 오픈소스 라이선스)
- 구성: 순수 파이썬 단일 파일 하나. 스트리밍(실시간 글자 흘려보내기)을 쓸 때만
httpx라는 부품 하나가 추가로 필요해요 - 동작 원리: Gemini 웹앱이 내부에서 쓰는 통신 규약을 리버스 엔지니어링(reverse engineering, 역분석 — 겉으로 드러난 동작을 거꾸로 뜯어보며 작동 방식을 알아내는 것) 해서, OpenAI 양식과 Gemini 양식을 양방향으로 변환합니다. (이 부분은 깊게 몰라도 돼요. "통역기"라고만 기억하시면 충분합니다.)
��쉽게 말해, 이미 쓰고 있는 Gemini를 OpenAI 도구들이 그대로 갖다 쓰게 만들어 주는 통역 어댑터예요. 전체 흐름을 한 장으로 보면 이래요.

실제로 이렇게 동작해요
"말로는 그럴듯한데 진짜 되는 거 맞아?" 싶으실 거예요. 그래서 제가 직접 돌려봤어요. 제 PC에서 이 프록시를 포트(port, 프로그램이 통신하려고 쓰는 출입구 번호) 8081 로 띄워두고, 두 가지를 호출해 확인했습니다.
첫째, 모델 목록을 물어봤어요. OpenAI 도구들은 "너 어떤 AI 모델 쓸 수 있어?" 하고 GET /v1/models 로 물어봅니다. 그랬더니 로그인된 Gemini의 모델 6종이 OpenAI 형식 목록으로 그대로 나왔어요.

쓸 수 있는 모델은 이렇게 나뉘어요.
| 모델 이름 | 이런 일에 써요 |
|---|---|
gemini-3.5-flash | 빠르고 가벼운 범용 작업 (분석·요약·간단한 글) |
gemini-3.5-flash-thinking | 깊게 고민하는 작업 (긴 글·복잡한 추론, 최장 ~2만 자) |
gemini-3.5-flash-thinking-lite | 사고 깊이를 상황에 맞게 자동 조절 |
gemini-3.1-pro | 가장 고품질 (단, 유료 쿠키 필요 — 뒤에서 설명) |
gemini-auto | 알아서 적당한 모델을 골라줌 |
gemini-flash-lite | 가장 가볍고 빠른 응답 |
여기에 작은 옵션이 하나 더 있어요. 모델 이름 뒤에 @think=N 을 붙이면 사고 깊이를 조절할 수 있어요. 0 이 가장 깊게 고민하는 거고, 4 가 가장 얕고 빠르게 답하는 거예요. 예를 들어 gemini-3.5-flash-thinking@think=0 처럼 쓰면 "최대한 깊이 생각해서 답해줘"라는 뜻이에요.
둘째, 진짜로 대화를 걸어봤어요. OpenAI 양식으로 POST /v1/chat/completions 에 gemini-3.5-flash 모델로 "한 문장으로: 바이브 코딩이 뭐야?" 라고 보냈더니, Gemini가 OpenAI 형식 그대로 답을 돌려줬어요.

답변 내용은 "바이브 코딩은 원하는 걸 말로 설명하면 AI가 실시간으로 프로토타입·게임·웹페이지를 자동으로 만들어 주는 방식" 이라는 깔끔한 한 문장이었고, 응답 끝에 total_tokens: 36 이라는 사용량 표시까지 OpenAI 양식 그대로 찍혔어요. (토큰(token) 은 AI가 글자를 세는 단위예요. 36이면 아주 짧게 주고받았다는 뜻이에요.)
정리하면 — 모델 목록 조회도, 실제 대화도, 사용량 표시까지 OpenAI 양식 그대로 동작합니다. 통역이 제대로 된다는 걸 두 눈으로 확인한 셈이에요.
이 프록시가 통역할 줄 아는 기능은 이게 다가 아니에요.
- OpenAI 호환:
/v1/chat/completions,/v1/models를 드롭인(drop-in, 기존 걸 빼고 그대로 끼워 넣어도 작동하는) 대체로 제공 - tool calling(툴 콜링, 함수 호출 — AI가 직접 외부 기능을 호출하게 하는 것) 지원
- 웹 검색: Gemini가 원래 가진 실시간 검색 능력 사용
- 스트리밍(SSE 스트리밍, Server-Sent Events — 답을 한 글자씩 실시간으로 흘려보내는 방식) 지원
- Codex CLI (
/v1/responses) · Gemini CLI (/v1beta/models) 양식까지 호환 - 인증·배포: 설정 파일에 키를 넣으면 인증을 걸 수 있고, Docker(도커, 프로그램을 통째로 담아 옮기는 컨테이너 도구)·프록시 환경도 지원
우리는 이렇게 쓰고 있어요
이건 소개만 하는 게 아니라, 저희가 실제로 매일 쓰고 있는 도구예요.
디온웍스의 AI 에이전트 프로젝트 DGagent(디지에이전트) 가 이 프록시를 LLM 백엔드로 씁니다. LLM(Large Language Model, 거대 언어 모델 — AI의 두뇌 역할을 하는 모델) 백엔드란, 자동화 프로그램이 "생각이 필요할 때 물어보는 AI 창구"를 말해요. DGagent 는 그 창구를 OpenAI 양식으로 두드리는데, 그 뒤에서 답하는 건 web2api 를 통한 Gemini 인 거죠.
구체적으로 이렇게 나눠 써요.
- 네이버 블로그 글쓰기 스킬 — 품질이 중요한 본문 작성에는
gemini-3.1-pro를, 가벼운 분석·계획 단계에는gemini-3.5-flash를 씁니다. 둘 다 web2api(127.0.0.1:8081, 내 PC 안에서만 도는 주소) 를 경유해 호출해요. - 서이추(서로이웃) 댓글·인사말 생성 — 짧고 자연스러운 글이 많이 필요한 작업이라, 같은 web2api 경로로 가볍게 호출합니다.
핵심 가치는 한 줄로 요약돼요 — "Gemini 구독을 OpenAI 형식으로, 추가 API 비용 없이 내 자동화에 꽂아 쓴다." 이미 Gemini를 쓰고 있다면, 그 구독을 자동화의 두뇌로 재활용하는 셈이에요.
다만 솔직하게 덧붙이면, 저희도 뒤에 나오는 한계와 주의사항을 같이 알고 씁니다. 공식 API가 아니라는 점을 빼놓고 추천하면 안 되니까요. 그 부분은 아래에서 정직하게 말씀드릴게요.
한번 써볼까요?
설치가 정말 단출해요. 파일 하나에 부품 하나면 끝이에요.
# 스트리밍용 부품 httpx 설치 (이거 하나면 준비 끝)
pip install httpx
# 프록시 서버 실행 — 끝나면 http://localhost:8081/v1 로 열려요
python gemini_web2api.py
서버가 뜨면 이제 OpenAI 도구들이 붙을 수 있는 주소(http://localhost:8081/v1)가 생긴 거예요. 여기에 평소 쓰던 도구를 연결하면 됩니다.
방법 1 — curl 로 직접 호출 (터미널에서 바로 테스트할 때)
# OpenAI 양식 그대로 Gemini에게 질문 보내기
curl http://localhost:8081/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-your-key" \
-d '{"model":"gemini-3.5-flash","messages":[{"role":"user","content":"안녕!"}]}'
방법 2 — OpenAI 파이썬 SDK (코드에서 부를 때). 신기하게도 OpenAI용으로 쓰던 코드에서 주소만 바꾸면 그대로 Gemini가 답해요.
from openai import OpenAI
# base_url 만 우리 프록시로 바꿔주면 끝
client = OpenAI(
base_url="http://localhost:8081/v1",
api_key="sk-your-key",
)
resp = client.chat.completions.create(
model="gemini-3.5-flash",
messages=[{"role": "user", "content": "안녕!"}],
)
print(resp.choices[0].message.content)
방법 3 — Cherry Studio · ChatBox 같은 채팅 앱 (코딩 없이 클릭으로). 이런 OpenAI 호환 챗 앱에서는 설��정 화면에 두 가지만 넣으면 돼요.
- Base URL(기본 주소):
http://localhost:8081/v1 - Model(모델):
gemini-3.5-flash-thinking
방법 4 — Gemini CLI 연결 (터미널에서 제미나이 명령어 도구를 쓸 때)
# 인증 키는 안 써도 되니 none 으로 두고
export GEMINI_API_KEY=none
# 제미나이 도구가 바라볼 주소를 우리 프록시로 지정
export GOOGLE_GEMINI_BASE_URL=http://localhost:8081
# 실행
gemini
참고:
Authorization: Bearer인증은 선택이에요. 설정 파일의api_keys항목이 비어 있으면 인증 없이 누구나 호출할 수 있고, 키를 채워두면 그 키를 가진 요청만 받아들여요. 내 PC에서만 쓸 거면 비워둬도 괜찮지만, 외부에 열어둘 거면 꼭 키를 채우세요.
클로드 코드 터미널에서는 이렇게
이 도구는 OpenAI 호환이라, 클로드 코드 자체보다는 Codex CLI · Gemini CLI · 각종 챗 앱에 Gemini를 꽂아주는 게 진짜 쓸모예요. 그래도 클로드 코드 대화창 안에서 서버를 띄우고 점검하는 건 편하니, 그 흐름을 정리해 드릴게요.
클로드 코드 대화창에서
!를 맨 앞에 붙이면 터미널 명령어를 바로 실행할 수 있어요.
# 클로드 코드 대화창 안에서 부품 설치 (앞��에 ! 붙임)
! pip install httpx
# 클로드 코드 대화창 안에서 프록시 서버 실행 (앞에 ! 붙임)
! python gemini_web2api.py
서버가 잘 떴는지 확인하고 싶으면, 다른 대화 줄에서 모델 목록을 한 번 두드려 보세요.
# 모델 목록이 OpenAI 형식으로 나오면 정상 (앞에 ! 붙임)
! curl http://localhost:8081/v1/models
이제 다른 도구를 이 프록시에 붙일 차례예요. 환경변수(environment variable, 프로그램이 참고하는 설정값) 두 줄이면 Gemini CLI 가 우리 프록시를 바라보게 됩니다. (이건 명령어라서 ! 를 붙여 실행해요.)
# Gemini CLI 가 우리 프록시를 바라보게 설정 (앞에 ! 붙임)
! export GEMINI_API_KEY=none && export GOOGLE_GEMINI_BASE_URL=http://localhost:8081
만약 클로드한테 말로 시키고 싶다면, 아래처럼 부탁해도 돼요. (이건 명령어가 아니라 AI에게 거는 부탁이라 ! 를 붙이지 않아요.)
이 폴더의 gemini_web2api.py 를 실행해서 8081 포트로 프록시를 띄워줘.
서버가 뜨면 /v1/models 를 호출해서 모델 목록이 OpenAI 형식으로 나오는지
확인하고, 결과만 짧게 정리해줘.
확인 포인트: curl http://localhost:8081/v1/models 를 쳤을 때 위에서 본 6개 모델이 목록으로 나오면, 통역사가 제자리에서 잘 일하고 있는 거예요.
이런 한계도 알아두세요
이 도구를 추천하면서 좋은 점만 말하면 그건 정직하지 않아요. 만든이가 README 에 솔직히 적어둔 한계를, 비개발자 눈높이로 그대로 옮겨드릴게요. 알고 쓰면 실망할 일이 없어요.
- 이미지 입력은 안 돼요. 그림·사진을 넣어서 "이거 뭐야?" 하고 묻는 멀티모��달(multimodal, 글자 외에 이미지·소리도 함께 다루는 것) 은 지원하지 않아요. 글자(텍스트) 전용이에요.
- 유료 쿠키가 없으면 진짜 Pro 가 아니에요.
gemini-3.1-pro를 골라도, 진짜 Pro 권한이 없으면 조용히 Flash 모델로 폴백(fallback, 안 되면 대신 다른 걸로 떨어뜨리는 것) 돼요. 화면엔 "Pro"라고 떠도 실제 두뇌는 Flash 일 수 있다는 뜻이에요. 진짜 Pro 를 쓰려면 Gemini Advanced(제미나이 유료 구독) 계정의 쿠키가 필요해요. (쿠키(cookie) 는 브라우저가 로그인 상태를 기억하려고 들고 있는 작은 인증 표예요. 추출 방법은 README 에 안내돼 있어요.) - 단일 턴(single turn)이에요. 매 요청이 각각 독립된 대화로 처리돼요. "아까 말한 그거"처럼 이전 맥락을 자동으로 기억하지 않아요. 이어지는 대화를 원하면, 앞 내용을 매번 질문에 같이 담아 보내서 흉내 내야 해요.
- 속도 제한이 있을 수 있어요. 구글이 과한 요청을 막을 수 있어요. 막히면 자동으로 다시 시도하지만, 너무 많이 쓰면 차단될 수 있어요.
- 공식 경로가 아니라는 점. 이건 정식 Gemini API 가 아니라, 내 브라우저에 로그인된 Gemini 웹 세션을 빌려 쓰는 방식이에요. 그래서 구글 약관(ToS, Terms of Service — 서비스 이용 규칙)·계정 관점에서는 비공식 경로, 즉 회색지대예요. 겁먹을 필요는 없지만, 개인 학습·실험용으로, 본인 계정 책임하에 쓰는 도구라는 점은 꼭 기억해 주세요.
이 한계들을 알고 나면, "어디에 쓰면 좋고 어디엔 안 맞는지"가 또렷해져요. 가볍게 글 쓰고 분석하고 자동화에 두뇌를 붙이는 용도로는 훌륭하고, 이미지 분석이나 상용 서비스의 핵심 두뇌로 쓰는 데에는 맞지 않아요.
이런 분께 추천해요
gemini-web2api 는 "이미 쓰고 있는 Gemini를 OpenAI 도구들에 공짜로 꽂고 싶다" 는 분께 딱이에요. 특히 이런 세 분께 추천드려요.
-
Gemini 구독은 있는데 API 비용은 아끼고 싶은 바이브 코더 — 매달 Gemini 구독료를 이미 내고 있다면, 그 구독을 자동화 두뇌로 한 번 더 우려먹을 수 있어요. 정식 API 키를 따로 발급받고 사용량만큼 돈을 내는 부담 없이, 개인 실험·학습용으로 부담 없이 굴려볼 수 있어요.
-
Codex CLI · Cherry Studio 같은 OpenAI 도구에 Gemini를 붙이고 싶은 분 — 손에 익은 OpenAI 호환 도구는 그대로 두고, 뒤에서 답하는 두뇌만 Gemini로 바꾸고 싶을 때 좋아요. 도구를 새로 배울 필요 없이 주소 한 줄만 바꾸면 되니까요.
-
자동화에 무료 LLM 백엔드가 필요한 1인 개발자 — 저희 DGagent 처럼, 작은 자동화 프로그램에 "생각하는 창구"가 필요한 분께 잘 맞아요. 단, 위의 한계 섹션을 꼭 함께 읽고 "개인·실험용"이라는 선을 지키며 쓰시길 권해요.
참고 링크
- 공식 GitHub: Sophomoresty/gemini-web2api
- 만든이: Sophomoresty (라이선스 MIT)
- 개발 도움받은 곳: 만든이가 README 에서 이 프로젝트의 개발 agent(개발을 돕는 AI 도구)로 GenericAgent 를 썼다고 밝히고 있어요
- OpenAI 파이썬 SDK: github.com/openai/openai-python
▸개정 이력1건
- v12026-06-27초판
이 글이 도움이 되었나요?